
Now that some programming fundamentals are in our tool belt and we know a bit about classes, we're ready to connect our ruby code to our SQL database.
Why?
It's a good question - why do we care?
- It's easier.
SQL isn't really a programming language - at least not one that you can build an application with. It's a critical part of the technical stack (the technologies used in an application), but there's no easy way to expose SQL data to a user or create business logic around how data gets created. For that, we need a programming language like ruby. We could figure out how to connect the 2 technologies and write raw SQL statements (and sometimes we do), but then we would need to do a lot of context switching. It's nicer to just focus on 1 language (e.g. ruby) and worry less about raw SQL code. - It's more consistent.
Along the same lines, if we can just work in our main application code, we can build a team and focus our resources around that expertise. There's an organizational benefit to doing so. Perhaps we need 1 or 2 SQL experts, but the majority of developers can just focus on the application layer. - It's more flexible.
Lastly, sometimes we want to switch the underlying database technology. In fact, in this course we're using sqlite in our development, but when we eventually want to ship our code to production (i.e. make it live for users), we'll want to upgrade to an enterprise version of SQL (e.g. postgresql). If we were writing raw SQL, our code might need to change when the database software changes. But if we're using ruby to talk to our database, very little code will need to change to accommodate the new software.
ActiveRecord (ORM)
So how do we connect ruby code with SQL? We use an ORM, Object-relational mapper. Every programming language that needs to talk to a database has an ORM - in ruby, we'll use a library called ActiveRecord. It's a bridge that gives us a robust but easy-to-write ruby code that will translate to SQL without us even thinking about it.
Using ActiveRecord, we can create custom classes called Models that are dedicated to representing a single table in the database. For example, an events table in our database would have a matching Event model in our code. And instances of the Event model represent rows in the events table. Let's see it in action.
Go to this lesson's repository and open it in Codespaces. Let's open the file 2-models.rb from the code-along directory. There's a bit of code already in the file, we'll come back to that later. There are some code comments here and we'll follow them as we learn about models.
Domain Model
Since models represent tables in the database, we need a domain model to work with. We'll use the CRM domain model from our domain modeling lesson:
- Wireframes & User Stories
- Domain Model (scroll to the bottom for the final structure)
From the previous lesson on migrations, this application now has several tables from the domain model: companies, contacts, salespeople, and activities. There are a couple ways to check them out.
First, we can open our sqlite database just like we used to. The sqlite database file is in the db directory. To open it from terminal, run:
sqlite3 db/development.sqlite3You'll be at the sqlite prompt sqlite>. Use the .schema command to see what tables are in the database - you should see our 2 tables and their respective columns. Don't forget to .exit afterwards - we'll need to be back at the usual terminal prompt to run our ruby file.
Next, we can also check a ruby version of the schema. In the db directory, open the schema.rb file. This is ruby code (part of the ORM library) that mirrors the SQL schema. Again, you'll see the 2 tables that are already part of the database and their columns.
To interact with these tables, each has a corresponding model. In the app/models directory, open up the files company.rb and contact.rb.
class Company < ApplicationRecord
endclass Contact < ApplicationRecord
endThey're empty, but these model classes are the building blocks of our application.
Creating Data
So the tables exist, but what data is in them? We could go back into sqlite and use a SELECT statement to see the data. But let's start using ruby.
In the code-along/2-models.rb file, add the following line of code:
puts "There are #{Company.all.count} companies."Then run the file with rails runner code-along/2-models.rb. The output should be
There are 0 companies.Company.all.count is calling a method on the Company class which is talking to the database and asking for a count of the rows in the companies table. In fact, under the hood that .all method writes raw SQL that looks like
SELECT * FROM companiesAnd .all.count similarly writes SQL like
SELECT COUNT(*) FROM companiesTo prove it, open up the log/development.log file and scroll to the bottom. There's some noise there, but if you look closely you'll see that a SELECT COUNT(*) query was performed. (Side note: this log file tracks all of the application activity and is often used by development teams when trying to debug a tricky issue - it's very useful history.) If you want, you can hop back into the sqlite prompt and run the same SQL there too.
Ok, now we know the companies table is empty. Let's insert a new row. First, let's build a new instance of the Company class:
apple = Company.newThis is similar to how we built a new dog from the Dog class.
Next, let's assign the company's attributes one at a time:
apple["name"] = "Apple Inc."
apple["url"] = "https://apple.com"
apple["city"] = "Cupertino"
apple["state"] = "CA"These attributes match the columns in the table name, url, city, and state.
Last step, we want to actually save (i.e. INSERT) it into the database:
apple.saveAll together, the code looks like this:
apple = Company.new
apple["name"] = "Apple Inc."
apple["url"] = "https://apple.com"
apple["city"] = "Cupertino"
apple["state"] = "CA"
apple.saveHow do we know if it worked? The same ways we checked if the table was empty before. First, let's add another line of code checking the row count:
puts "There are #{Company.all.count} companies."When you run the file now, you should see
There are 0 companies.
There are 1 companies.Not grammatically correct, but at least it seems like our insert worked. You can also check the log file to see if the SQL insert statement is there. And last, you can hop into the sqlite prompt once again and check the results of a SQL select statement. We're going to stop referencing these checks and trust the ruby code, but feel free to use them whenever you feel they're useful.
Let's insert another row and another count. We'll leave the url column blank this time (we'll update it later).
amazon = Company.new
amazon["name"] = "Amazon.com, Inc."
amazon["city"] = "Seattle"
amazon["state"] = "WA"
amazon.save
puts "There are #{Company.all.count} companies."The output is now
There are 0 companies.
There are 1 companies.
There are 2 companies.There's another way to assign attributes that you may see if you're doing any googling. We'll start with a new company instance:
tesla = Company.newAnd we'll assign the attributes:
tesla["name"] = "Tesla, Inc."
tesla["url"] = "https://tesla.com"
tesla["city"] = "Palo Alto"
tesla["state"] = "CA"We do this so often that the ActiveRecord library gives us a shortcut:
tesla.name = "Tesla, Inc."
tesla.url = "https://tesla.com"
tesla.city = "Palo Alto"
tesla.state = "CA"Instead of using the hash syntax where we use square brackets and the hash key, we can use this dot-notation (. + the name of the attribute). These are called "setter" methods (because they set, or write, attribute data). They're no different than what we've been doing, but some developers prefer this dot-notation syntax. For now, we'll keep using the hash syntax, but you can use whichever you prefer. We'll also see some other ways to assign attributes later on.
And now just save the record:
tesla.saveAll together, it looks like this (along with the count):
tesla = Company.new
tesla["name"] = "Tesla, Inc."
tesla["url"] = "https://tesla.com"
tesla["city"] = "Palo Alto"
tesla["state"] = "CA"
tesla.save
puts "There are #{Company.all.count} companies."Reading Data
Now that there is data in the table, let's look at how to query data. We've actually already used a query: Company.all. The .all method unsurprisingly will return all records from the table. It writes a SELECT * statement from the corresponding table.
To filter down from all records, we can use the .where method with a hash of conditions. For example, if we want all companies in the state of California, we can use
Company.where({"state" => "CA"})This returns an array of records. At a glance, the returned object is called an ActiveRecord::Relation, but if you look closely you'll see the square brackets [] which indicates this is an array - a special kind of array, but still an array. We can be more specific by using multiple conditions
Company.where({"state" => "CA", "name" => "Apple Inc."})At this point, there should only be 1 "Apple Inc." company in our database (certainly only 1 that is in California). If we want to pull out that object from the array, we use its index [0]:
company = Company.where({"state" => "CA", "name" => "Apple Inc."})[0]
puts companyWhen we know there's only one row in our table matching the criteria, the use of [0] to find the first element in the array gets annoying. So, as with many things in ruby and rails code, there's a more succinct way:
company = Company.find_by({"state" => "CA", "name" => "Apple Inc."})
puts companyThe find_by method is the same as the above, but it reads a little nicer - it's obvious in the code that we're expecting only 1 result from our query.
If you add this code to the code-along file and run it, you'll see something a little odd:
#<Company:0x00007f785cd9cc00>The characters you see will be different, but it will look similar. This is the identifier of where in the computer's memory this object is being held. It's not very useful to us - it would be great to see the object with the underlying data from that row in the table. To do so, we'll use puts company.inspect which will "inspect" or open up the object. Once we make the change, the output is more useful.
#<Company id: 1, name: "Apple Inc.", url: "https://apple.com", city: "Cupertino", state: "CA", slogan: nil, created_at: "2022-02-01 09:53:44.087974000 +0000", updated_at: "2022-02-01 09:53:44.102738000 +0000">Note, your output will be slightly different - the created_at and updated_at timestamps will obviously reflect when you ran your code. And the id may be different depending on how many times you've run the file.
So what is this thing? It's the row from our companies table that we queried for - the one with the name "Apple Inc." and the state "CA". Look a little closer at it and you may notice that it sort of looks like a hash with key-value pairs! If we check its class (puts company.class), we'll find out that it's not a Hash - it's a Company, meaning it comes from our custom Company class. That might not be surprising considering when we inserted this row, we used Company.new. But it does behave like a hash in many ways.
Now that we have an individual row from the database, let's read its individual values. Imagine we want to create a sentence like "Visit the Apple Inc. website at https://apple.com". To read specific attributes (i.e. column values), we'll use hash syntax:
puts company["name"]
puts company["url"]This outputs
Apple Inc.
https://apple.comSimilar to when we were assigning attributes, if you do some googling, you may see it written slightly differently using dot-notation:
puts company.name
puts company.urlThese are called "getter" methods (because they get, or read, attribute data) and, again, some developer prefer them. But we'll keep using the hash syntax:
puts "Visit the #{company["name"]} website at #{company["url"]}"Updating Data
We can now create data and read data. Another common behavior is modifying an existing row in the database. We actually already know the code for updating - individual assignment and .save. Let's update the url column for Amazon.
In the code-along file, we need to first query to find the Amazon row.
amazon = Company.find_by({"name" => "Amazon.com, Inc."})And now we can assign a value to the url column and save the row.
amazon["url"] = "https://www.amazon.com"
amazon.saveThe .save method is interesting here. Previously, we used it to insert a new row. But here, we're using it to update an existing row. If you open up the log/development.log file, you'll see the corresponding SQL is an UPDATE companies statement. If we were writing our own SQL, we would need a lot of logic to determine if we should use an INSERT or an UPDATE, but the ORM takes care of it for us and we can write some simple ruby code. Lucky us!
And that's it, we've updated the record. We can verify by pulling the row back out of the database just like we did before:
company = Company.find_by({"name" => "Amazon.com, Inc."})
puts company.inspectAnd now you'll see that url is updated.
#<Company id: 1, name: "Amazon.com, Inc.", url: "https://www.amazon.com", city: "Seattle", state: "WA", created_at: "2022-02-01 09:53:44.087974000 +0000", updated_at: "2022-02-01 10:03:44.102738000 +0000">Note that the updated_at timestamp has changed also since it reflects the last time this row was edited.
Deleting Data
Occasionally, we need to remove a row from the database - maybe due to an error when inserting or maybe because a record is no longer relevant to our application. Whatever the reason may be, there is a method .destroy that will permanently delete a row.
Let's first insert a new row that has a mistyped name:
company = Compan.new
company["name"] = "Tesler"
company.saveWe have it already stored in this variable, but let's pretend that we need to query it from the database since that's a more common use case.
tesler = Company.find_by({"name" => "Tesler"})Now we can delete it:
tesler.destroyAdding a few puts Company.all.count lines of code before and after the .destroy will clarify that there were 4 companies and now there are 3. We can also check out the log file to see the corresponding SQL DELETE statement. You'll notice that just as we instructed in the SQL unit, there's a WHERE id = ... clause to ensure only the intended row is deleted.
Resetting the database
At some point, you may have realized that we've executed this 2-models.rb file several times and yet the table hasn't grown - it still only has 3 rows. How? Shouldn't the table grow by 3 new rows each time the file runs? Where are all the previously inserted rows?
Look back up at the top of the file at the code Company.destroy_all. That line of code might make more sense now. Each time this file runs, the first thing that happens is this line of code deletes all the rows in the companies table. Doing so ensures you can rerun this file as many times as you want without creating duplicate rows. This also explains why the id values for your rows may differ - they will auto-increment and never be reused, so if you have 3 rows and run the file 3 times, the id values will be 7, 8, and 9.
Just be careful!!! Running this file deletes all of the rows in this table - not just the rows created in this file. Eventually the table will have more data created outside of this file and then we probably should avoid running this file. It's only safe for now because we're starting with an empty table.
🚨 TL;DR - The .destroy_all method is dangerous, so use it with extreme caution.
Cheatsheet
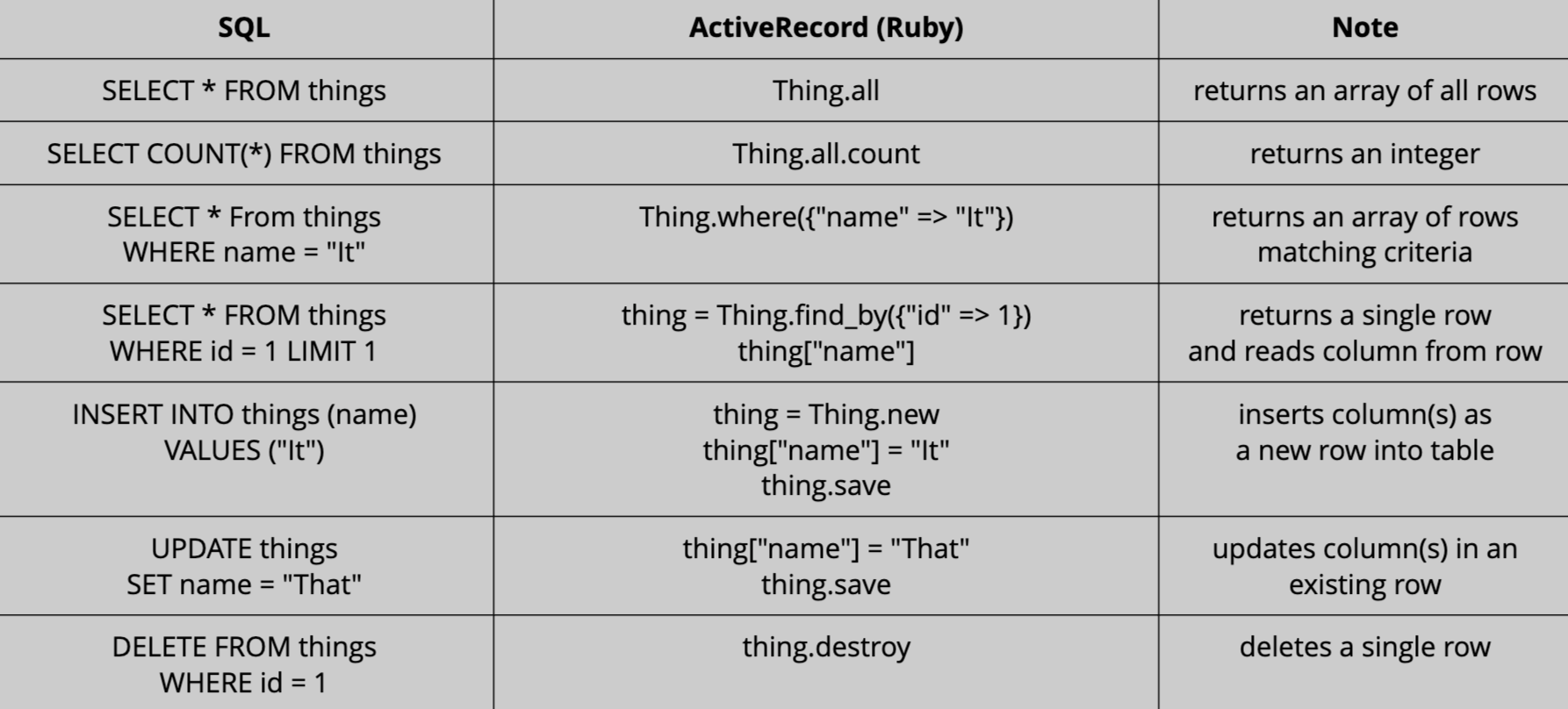
Inheritance
One final note - how do our models know about all these methods? Remember back in the classes unit, we had to tell our Dog class how to speak with a method. Where are the .all and the .where and the .find_by and the .save methods?
If we look again at the code in the model, there's a tiny bit of code < ApplicationRecord - tiny but powerful.
class Company < ApplicationRecord
endAs a programming concept, we say that our Company class inherits from the ApplicationRecord class (which is part of the ActiveRecord ORM library we're using). Inheritance means that our model, which appears to have no custom code in it, gets all the methods and functionality defined in ApplicationRecord. If we were to go look at the source code for that class, we would find the methods we've been using.
For models that correspond with a database table, that tiny bit of inheritance code takes care of connecting the model with the database table and providing all of the ORM methods that help us interact with the table.
Inheritance is another topic that we could spend weeks on, but isn't that important to our current goals. We're just pointing it out here so that you don't think it's all magic and you can explore it more on your own if you so choose.
Lab
Time for a lab to practice. Instructions are in the file 2-models.rb in the labs directory.